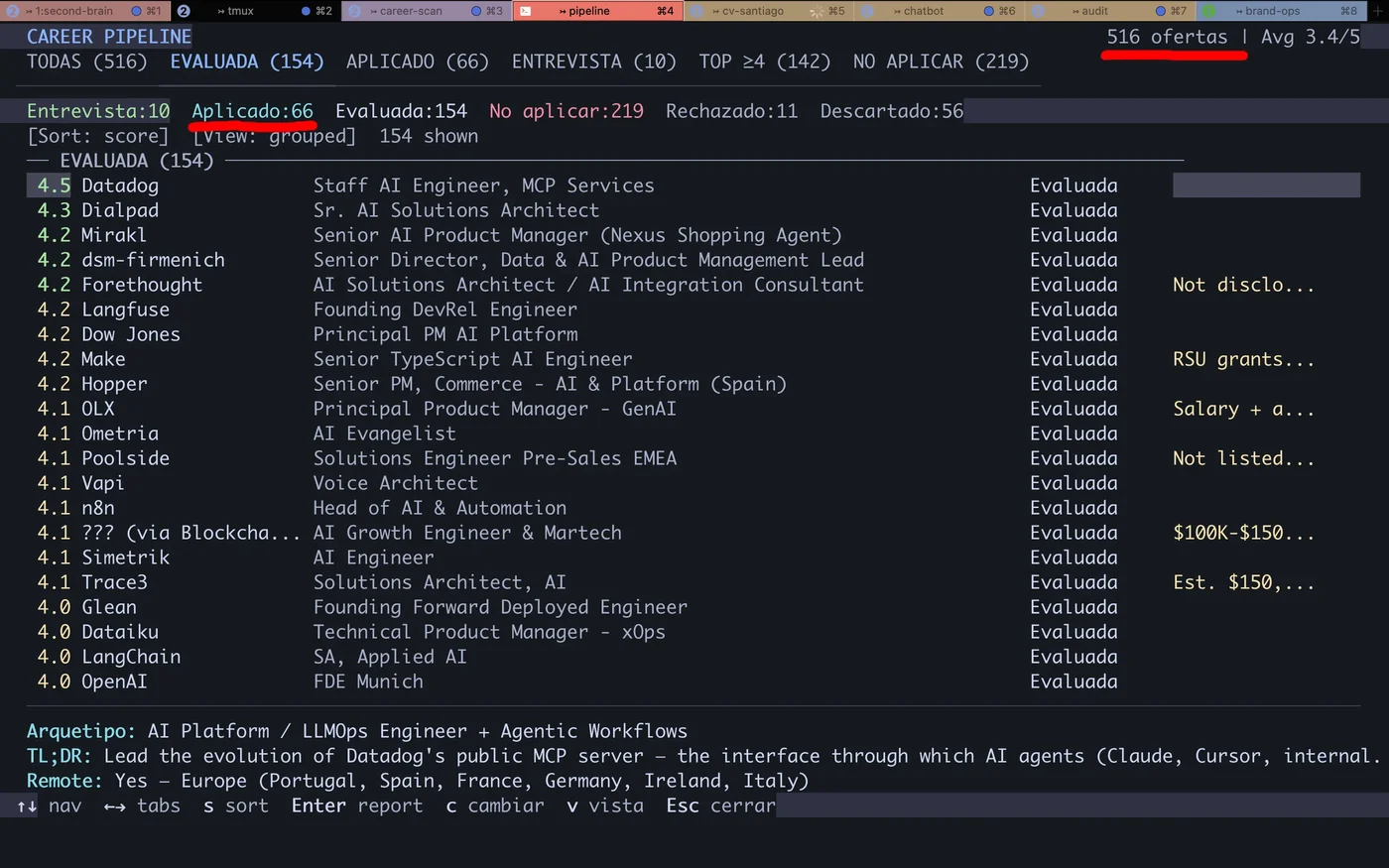
I no longer apply to jobs. A multi-agent system evaluates them, generates my personalized resume, and prepares the application. I review and decide. After 15 years building autonomous vehicle systems at Google, Uber, and Pronto.ai, I knew how to ship production systems under pressure. What I did not have was an efficient way to target the right AI Developer and DevOps roles. So I built one.
Career-Ops is an AI-powered job search tool built as a multi-agent system: reads job descriptions, scores them across 10 dimensions, generates AI resumes per listing, and automates job applications. I review and decide. The AI does the analytical work. The same engineering discipline that kept self-driving cars on the road now keeps my job search on track.
The Problem#
Searching for AI Developer, DevOps/SRE, and Embedded/Robotics roles means navigating a fragmented market. Each offer requires reading the JD, mapping your skills against requirements, adapting the CV, writing personalized responses, and filling 15-field forms. Multiply that by 10 offers per day.
Repetitive reading.
70% of offers are a poor fit. You find out after reading 800 words of JD.
Generic CVs.
A static PDF cannot highlight the proof points relevant to each specific offer.
Manual forms.
Every platform asks the same questions in different formats. Copy-paste 15 times per application.
No tracking.
Without a system, you forget where you applied. Duplicate effort or lose follow-up entirely.
Zero feedback.
Apply, wait, and never know if the problem was fit, the CV, or timing.
Cross-domain targeting.
AI, DevOps, and Embedded roles live on different boards, use different keywords, and attract different recruiters. One search strategy does not cover all three.
The work is not hard. It is repetitive. And repetitive work gets automated.
The 12 Modes — Multi-Agent System#
Career-Ops is not a script or an auto-apply bot. It is a multi-agent system with 12 operational modes, each a Claude Code skill file with its own context, rules, and tools. An agent that reasons about the problem domain and executes the right action.
Why Modes, Not One Prompt
Precise context.
Each mode loads only the information it needs. auto-pipeline skips contact rules. apply skips scoring logic.
Testability.
One mode gets tested in isolation. Changing PDF logic never touches evaluation.
Independent evolution.
Adding a new mode never breaks existing ones. Training mode shipped 3 weeks after first deploy.
auto-pipelineFull pipeline: extract JD, evaluate A-F, generate report, PDF, and tracker entry.
ofertaSingle-offer evaluation with 6 blocks: summary, CV match, level, compensation, personalization, interview.
ofertasMulti-offer comparison and ranking.
pdfATS-optimized PDF personalized per offer with proof points and keywords.
pipelineBatch URL processing from inbox.
scanOffer discovery: navigates job boards and careers pages of target companies. Many offers never appear on aggregators.
batchParallel processing with conductor + workers. Simultaneous URLs in queue.
applyInteractive form-filling with Playwright. Reads the page, retrieves cached evaluation, generates responses.
contactoLinkedIn outreach helper.
deepDeep company research.
trackerApplication status dashboard.
trainingEvaluates courses and certifications against the North Star.
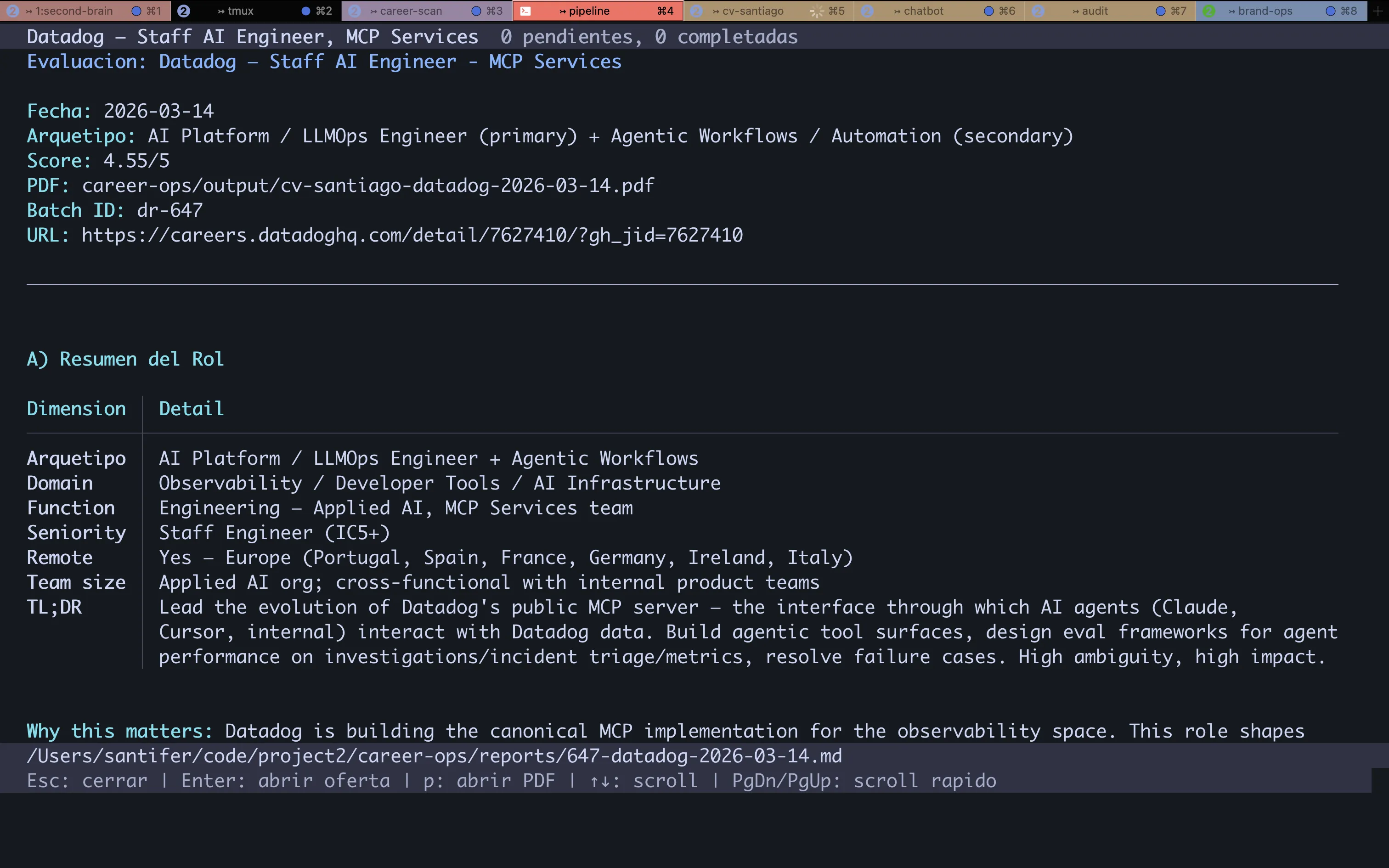
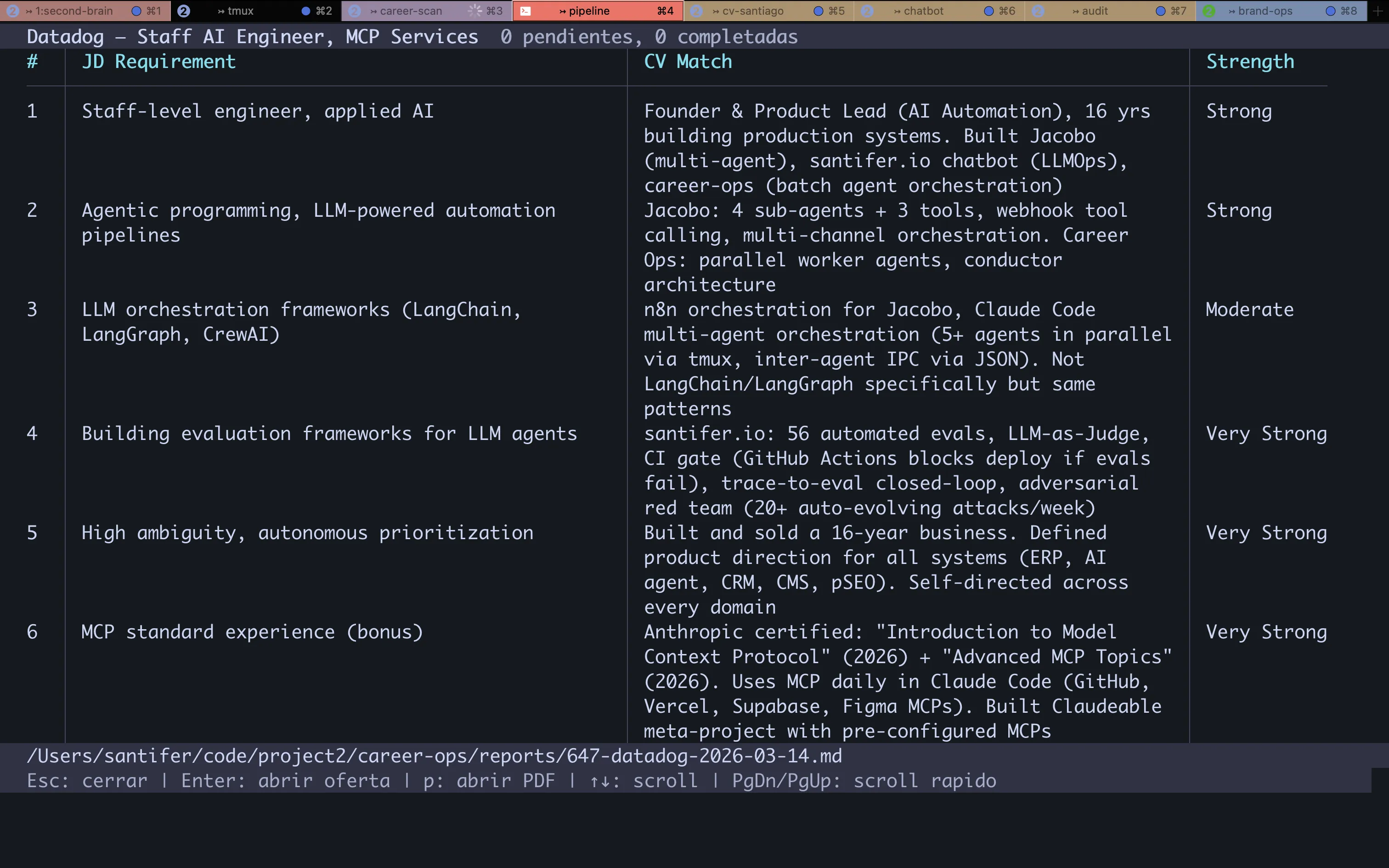
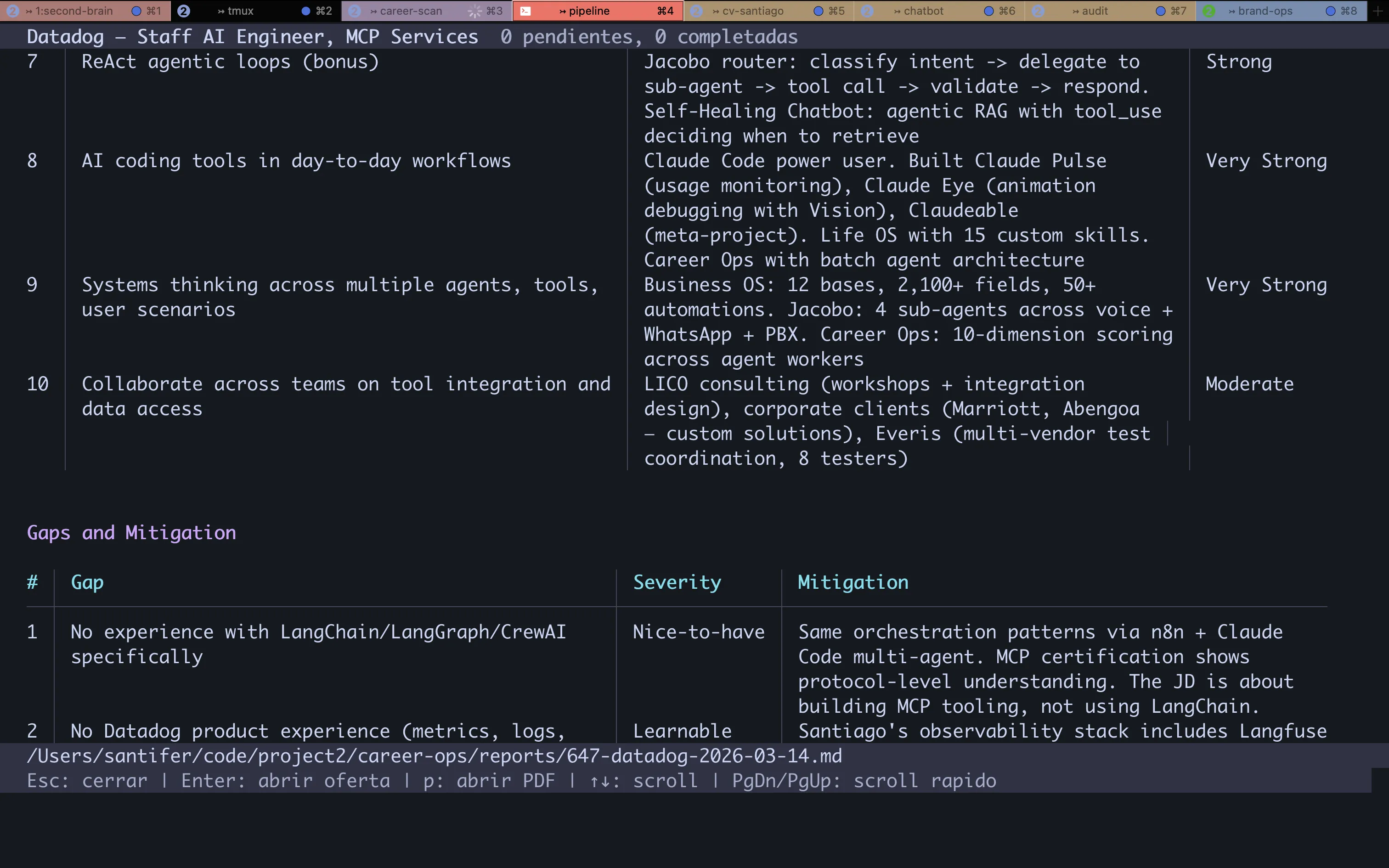
10-Dimension Scoring#
Every offer runs through an evaluation framework with 10 weighted dimensions. The output: a numeric score (1-5) and an A-F grade. Not all dimensions carry equal weight — Role Match and Skills Alignment are gate-pass: if they fail, the final score drops.
| Dimension | What It Measures | Weight |
|---|---|---|
| Role Match | Alignment between requirements and CV proof points | Gate-pass |
| Skills Alignment | Tech stack overlap | Gate-pass |
| Seniority | Stretch level and negotiability | High |
| Compensation | Market rate vs target | High |
| Geographic | Remote/hybrid/onsite feasibility | Medium |
| Company Stage | Startup/growth/enterprise fit | Medium |
| Product-Market Fit | Problem domain resonance | Medium |
| Growth Trajectory | Career ladder visibility | Medium |
| Interview Likelihood | Callback probability | High |
| Timeline | Closing speed and hiring urgency | Low |
Score Distribution
21
Score >= 4.5 (A)
52
Score 4.0-4.4 (B)
71
Score 3.0-3.9 (C)
51
Score < 3.0 (D-F)
74% of evaluated offers score below 4.0. Without the system, I would have spent hours reading JDs that never fit.
The Pipeline#
auto-pipeline is the flagship mode. A URL goes in, and out comes an evaluation report, a personalized PDF, and a tracker entry. Zero manual intervention until final review.
Extract JD.
Playwright navigates to the URL, extracts structured content from the offer.
Evaluate 10D.
Claude reads JD + CV + portfolio and generates scoring across all 10 dimensions.
Generate report.
Markdown with 6 blocks: executive summary, CV match, level, compensation, personalization, and interview probability.
Generate PDF.
HTML template + keyword injection + adaptive framing. Puppeteer renders to PDF.
Register tracker.
TSV with company, role, score, grade, URL. Auto-merge via Node.js script.
Dedup.
Checks scan-history.tsv and applications.md. Zero re-evaluations.
Batch Processing
For high volume, batch mode launches a conductor that orchestrates parallel workers. Each worker is an independent Claude Code process with 200K context. The conductor manages the queue, tracks progress, and merges results.
200K
Context/worker
2x
Retries per failure
Fault-tolerant: a worker failure never blocks the rest. Lock file prevents double execution. Batch is resumable — reads state and skips completed items.
AI Resume Builder — Personalized#
A generic CV loses. Career-Ops works as an AI resume builder that generates a different ATS-optimized resume for each offer, injecting JD keywords and reordering experience by relevance. Not a template: a resume built from real CV proof points.
Extract 15-20 keywords from the JD.
Keywords land in the summary, first bullet of each role, and skills section.
Detect language.
English JD generates English CV.
Detect region.
US company generates Letter format. Europe generates A4.
Detect archetype.
Target archetypes map to AI Developer, DevOps/SRE, and Embedded/Robotics. The summary shifts based on the profile.
Select projects.
Top 3-4 by relevance. OpenClaw for agent/AI roles. Cloud Infrastructure for DevOps. AV experience for robotics/embedded.
Reorder bullets.
The most relevant experience moves up. The rest moves down — nothing disappears.
Render PDF.
Puppeteer converts HTML to PDF. Self-hosted fonts, single-column ATS-safe.


Target Archetypes
| Archetype | Primary Proof Point |
|---|---|
| AI Developer | OpenClaw (22-agent AI system, multi-agent orchestration) |
| DevOps / SRE | Cloud Infrastructure (Docker, CI/CD, monitoring pipelines) |
| Embedded / Robotics | Google Self-Driving Car Project + Pronto.ai (7 years AV systems) |
| Full-Stack AI | The Skate Workshop (React Native) + DALL-E Image Generator |
| Automation Engineer | OpenClaw + Whisper Walkie (end-to-end AI-powered tooling) |
Same CV. Multiple framings. All real — keywords get reformulated, never fabricated.
Before and After#
| Dimension | Manual | Career-Ops |
|---|---|---|
| Evaluation | Read JD, mental mapping | 10D automated scoring, A-F grade |
| CV | Generic PDF | Personalized PDF, ATS-optimized |
| Application | Manual form | Playwright auto-fill |
| Tracking | Spreadsheet or nothing | TSV + automated dedup |
| Discovery | LinkedIn alerts | Scanner: job boards + target company careers pages |
| Batch | One at a time | Parallel URL processing |
| Dedup | Human memory | URLs deduplicated automatically |
Results#
The system is in active production use. Career-Ops handles the analytical heavy lifting — evaluating offers, generating tailored resumes, and tracking applications — so I can focus on the roles that actually fit.
12
Operational modes
10
Scoring dimensions
3
Career tracks targeted
0
Fabricated credentials
Stack
Claude Code
LLM agent: reasoning, evaluation, content generation
Playwright
Browser automation: portal scanning and form-filling
Puppeteer
PDF rendering from HTML templates
Node.js
Utility scripts: merge-tracker, cv-sync-check, generate-pdf
tmux
Parallel sessions: conductor + workers in batch
Lessons#
Automate analysis, not decisions
Career-Ops evaluates offers. I decide which ones get my time. HITL is not a limitation — it is the design. AI filters noise, humans provide judgment.
Modes beat a long prompt
12 modes with precise context outperform a 10,000-token system prompt. Each mode loads only what it needs. Less context means better decisions.
Dedup is more valuable than scoring
Deduplicated URLs mean evaluations I never had to repeat. Dedup saves more time than any scoring optimization.
A CV is an argument, not a document
A generic PDF convinces nobody. A CV that reorganizes proof points by relevance, injects the right keywords, and adapts framing to the archetype — that CV converts.
Batch over sequential, always
Batch mode with parallel workers processes URLs while I do something else. The investment in parallel orchestration pays off on the first run.
The system IS the portfolio
Building a multi-agent system to search for AI and DevOps roles is direct proof of competence. Same discipline that shipped self-driving car systems — applied to career search.
FAQ#
Is this gaming the system?
Career-Ops automates analysis, not decisions. Every evaluation report is reviewed before I decide whether to apply. Every generated PDF is inspected to verify that keywords are reformulated from real experience, not fabricated. The apply mode fills form fields but stops before clicking submit — I make the final call on every application. This is the same HITL philosophy behind any CRM or applicant tracking system: the tool organizes, filters, and prepares, but a human provides the judgment. The system explicitly discourages applying to roles scoring below 4.0 out of 5, recommending against wasting both my time and the recruiter's time on poor-fit applications. Quality over quantity is a design principle, not a slogan.
Why Claude Code and not a script pipeline?
A script pipeline follows fixed rules — it cannot reason about context, weigh ambiguous signals, or generate narrative analysis. Career-Ops uses Claude Code as an LLM agent that reads the full job description, cross-references it against my CV and project proof points, and produces a 10-dimension evaluation with contextual reasoning for each score. It detects when a role title says Senior but the responsibilities suggest Staff level. It recognizes when a startup listing compensation as competitive likely means below market. It reformulates keywords from my real experience to match the JD vocabulary without fabricating skills I do not have. The output is a narrative evaluation report with specific rationale per dimension, not a template with blanks filled in. That reasoning capability is why an LLM agent outperforms any deterministic script for this task.
What does it cost to run?
Zero marginal cost per evaluation. Career-Ops runs on a Claude Max subscription, which covers all Claude Code usage across every project: portfolio development, OpenClaw development, and Career-Ops itself. Each evaluation uses approximately 4,000-6,000 input tokens for the JD plus CV context and generates around 2,000 tokens of evaluation output. Under the Max plan, this volume is well within the included capacity. There is no per-API-call billing, no token metering, and no usage caps that would throttle batch processing. The economics make it viable to evaluate every offer the scanner finds rather than pre-filtering manually.
Does the apply mode fill forms automatically?
The apply mode uses Playwright to navigate to the application form, take a snapshot of all visible fields, and read the page structure including labels, placeholders, and required field indicators. It then retrieves the cached evaluation report for that company and role, which contains the 10-dimension scoring, matched proof points, and relevant keywords. From this context, it generates coherent responses for each form field: cover letter text draws from the evaluation personalization section, the motivation question pulls from the company research, and skills questions reference the specific proof points that scored highest in the CV match dimension. Every generated response is displayed for my review before any field is filled. I approve, edit, or reject each answer individually. The submit button is never clicked by the system — that is always my action.
What happens when the scanner finds a duplicate?
The dedup system works in two layers. First, scan-history.tsv stores every URL the scanner has ever seen with a timestamp and source portal. Each new URL is checked against this file using exact string matching after normalization (stripping tracking parameters, trailing slashes, and query strings). Second, even if the URL is new, Career-Ops performs a fuzzy match against applications.md using a normalized company name plus role title comparison. This catches the common case where the same job is posted on multiple portals with different URLs. The company name is lowercased and stripped of suffixes like Inc or GmbH, and the role title is compared after removing seniority prefixes. If both layers pass, the offer enters the pipeline. If either catches a match, it is silently skipped. The result: zero duplicate evaluations.
Is it replicable?
Yes. Career-Ops is open source on GitHub. You need Claude Code with Playwright browser access enabled for portal scanning and form filling, plus a structured working directory following the data contract: cv.md as the canonical resume, a profile configuration file with your target roles and salary range, and a portals configuration listing the job boards and company career pages to scan. Each of the 12 operational modes is defined as a Claude Code skill file with its own context window, rules, and tool permissions. Fork the repository and customize the scoring dimensions, archetypes, and evaluation criteria for your own career profile. The onboarding flow walks you through setup step by step.
Related Systems#
Career-Ops demonstrates the same competencies as these systems. Each one is a full case study with architecture, metrics, and lessons.
Ask
Open the chat and ask how I built Career-Ops. Or check out OpenClaw and my other projects that demonstrate the same competencies.